Articles
Urban Development
May 13, 2026



In late 2020 we stood on a virtual Autodesk University stage and presented a workflow we had built together with Bonava, one of the largest residential developers in Northern Europe. The talk was called Connecting People and Algorithms: Generative Design for Informed Decisions. The recording and slides are still available on Autodesk's AU class archive.
Five years later, almost everything in that presentation has either been solved by the field, validated by what we built next, or quietly proven wrong in interesting ways. This is a retrospective on what we got right, what we got wrong, and what the missing piece turned out to be.
The collaboration started from a specific Bonava reality. They had invested heavily in standardizing their housing product. A library of predefined single-family typologies, each fully modeled in Revit, with accompanying drawings, documentation, and cost data. The product side was solved. The variable was the site.
Every new piece of land asked the same question. Given this parcel, this zoning envelope, this topography, and these regulatory constraints, how many of which houses should go where? And how do we answer that quickly enough to make an informed acquisition decision, rather than a gut-feel one?
The traditional answer was one architect, one site, one afternoon, one layout. Maybe two if there was time. Our proposal was different. Use generative design to produce hundreds of layouts in the same time it took to produce one, then compare them on measurable criteria.
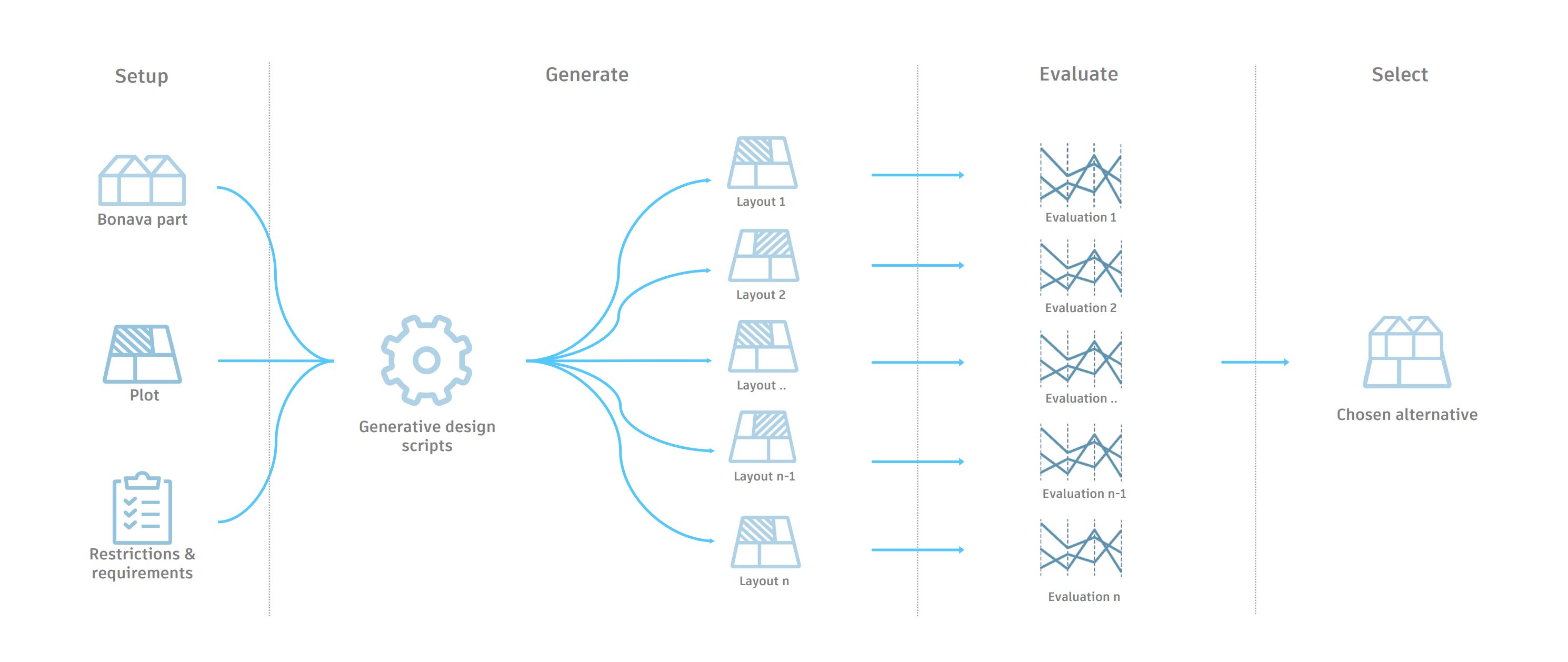
The technical architecture had three stages, each running on Dynamo and connected back to the Revit house library.
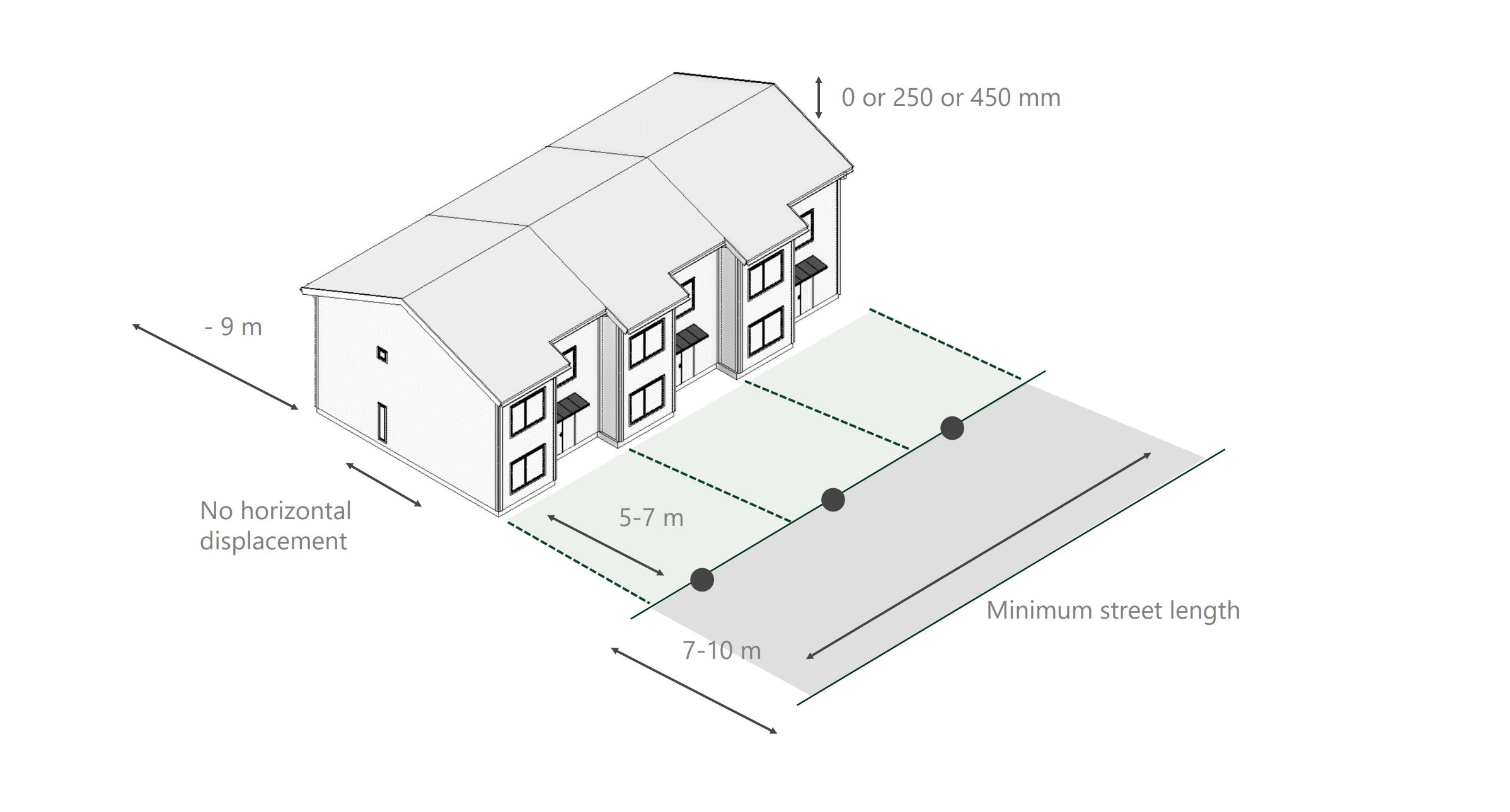
Generate. Place houses on the parcel within the buildable envelope, respecting setbacks, road access, and orientation preferences. Vary house types, rotations, and positions across hundreds of candidate layouts.
Evaluate. For each layout, compute a set of metrics. Hard values like unit count, gross floor area, parking ratio, and road length. Soft values like daylight on facades, distance to amenities, and view quality. Every option became a row in a table with twenty columns.
Evolve. Feed the best-performing layouts back into the generator as parents for the next round. Over multiple iterations, the population of layouts converged toward designs that performed well across the chosen criteria.
The mathematical engine behind this loop was a genetic algorithm. The interesting part was not the algorithm itself, which was already well understood. The interesting part was that the output was no longer a single design but a Pareto front. A set of layouts where each one was best at something, and the trade-offs between them were now visible and quantifiable.
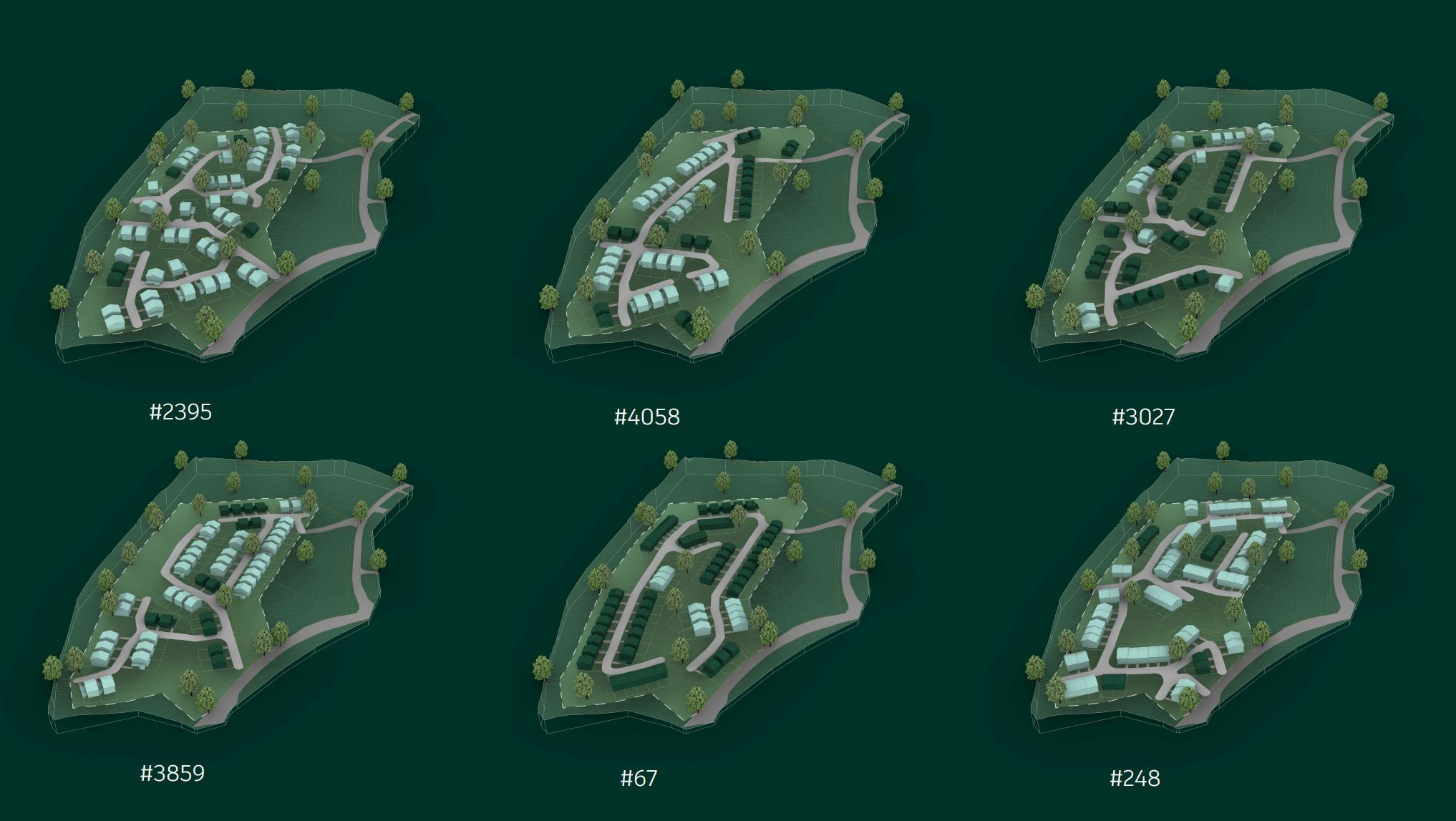
The audience reaction at the time was instructive. Property developers and business intelligence teams understood it instantly. They saw what we saw. A way to apply structured analysis to a phase of the project that had previously been pure intuition. A way to use Bonava's existing land bank as a queryable dataset rather than a portfolio of separate gut decisions.
Centralized knowledge instead of siloed workflows. Market data, customer insights, and architectural decisions all flowing into the same evaluation. For the business side, this was obvious value. Compressing the risk of an acquisition by knowing more about the site before signing was, and still is, the strongest argument for this kind of work.
Architects were more skeptical. Not because they disagreed with the goal, but because they could not see themselves in the workflow. If the algorithm placed the houses, what was the architect doing? If the algorithm chose between options, where did design judgment enter? These were good questions. They deserved better answers than we had in 2020.
The honest truth about the 2020 implementation is that it was technically fragile. Revit and Dynamo are powerful for what they were built for, which is detailed building information modeling. They were not built for fast iterative generation across hundreds of site configurations.
Every run was slow. Setting up a new site required manual configuration of constraints. The geometry engine had limits that forced compromises. If the parcel had unusual topography or complex zoning, the model often had to be simplified before it could be generated against. The whole pipeline worked, but it worked in spite of the tools, not because of them.
This was not a Bonava problem or an Autodesk problem. It was a problem of using a building information modeling stack for a job that was actually about early-stage feasibility. Different phase, different requirements, different tooling needed.
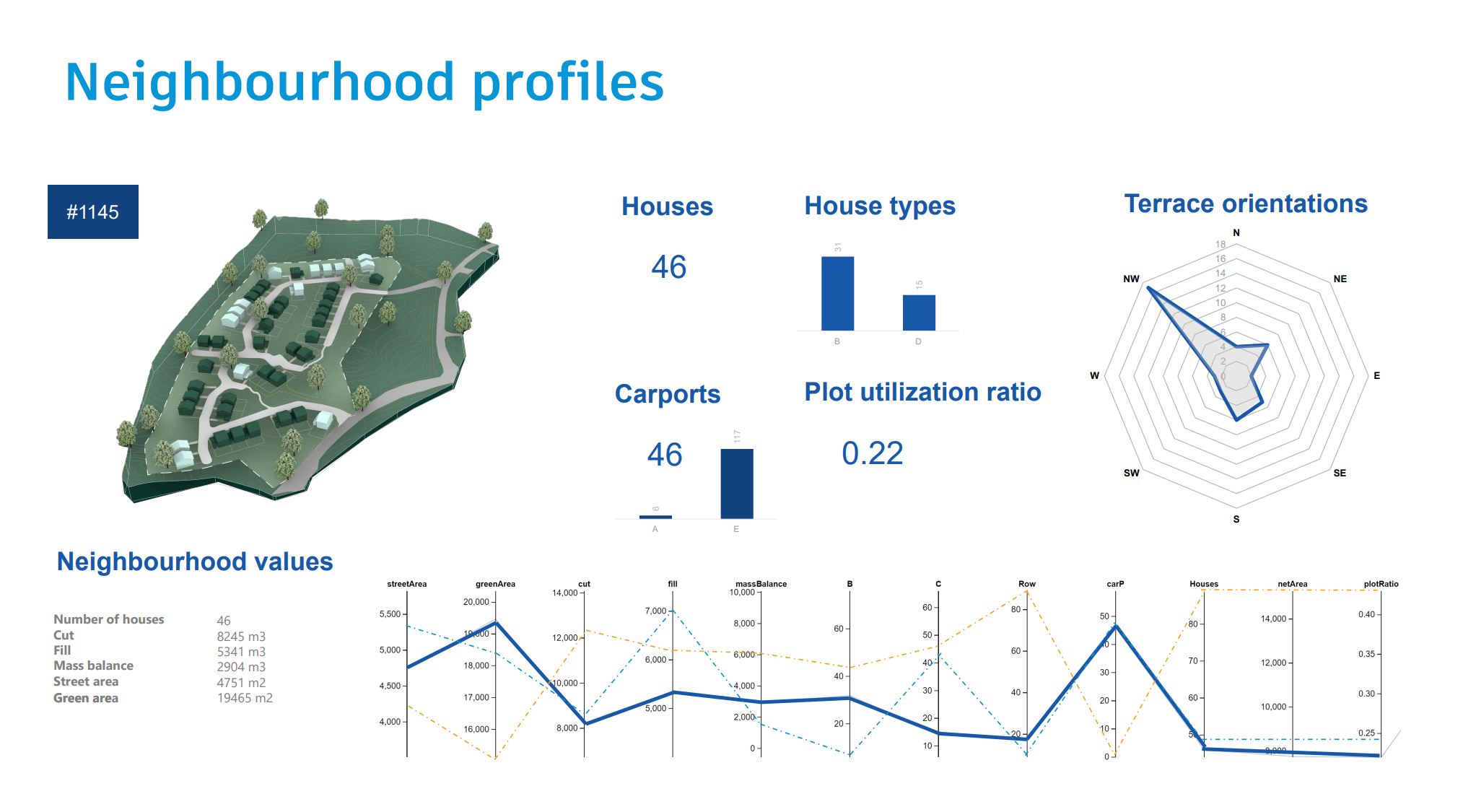
The second hard problem was harder than the technical one. When a developer or architect looked at a generated layout, they often could not tell why it existed. The genetic algorithm had selected it because it scored well on a weighted combination of criteria. But the path from criteria to layout was opaque. Why this rotation? Why this house type on this lot? The answer was always some version of "because the optimizer chose it," which is not an answer that survives a stakeholder meeting.
This is the deeper reason architects hesitated. Not skepticism about generative design as a concept, but skepticism about handing decisions to a system whose reasoning was not legible. A good design decision can be defended in a meeting. An algorithmic decision often could not.
We saw similar themes in the work coming out of the Netherlands at the time, particularly the early experiments at studios like Van Wijnen and academic work around computational massing. Everyone was hitting the same wall. The math worked, the optimization worked, and yet the output did not slot into how design teams actually made decisions.
The thing that has actually shifted in five years is not generative design itself. Genetic algorithms work the same way they did in 2020. What has shifted is what sits next to them.
Large language models can now read a layout and describe its reasoning. "This option placed the larger houses on the south edge to maximize ground-floor sunlight, accepted a longer access road, and reduced the parking buffer compared to option B." That sentence does not come from the optimizer. It comes from an AI that can interpret the optimizer's output in human terms.
That is the missing piece from 2020. The generative engine produces options. The interpretive layer makes them legible. Together, they let an architect or developer engage with the algorithm as a collaborator, rather than as a black box.
At the same time, the infrastructure layer has moved on. Modern parametric tools no longer need to be hosted inside a BIM environment. Hektar runs on a dedicated computational backend designed for early-stage iteration, with a typology library and constraint engine purpose-built for the problem. The fragility we lived with in 2020 is not the constraint anymore.
If we ran the Bonava workflow today, the architecture would look different in three ways.
First, the loop would be interactive rather than batch. A developer or architect would adjust a constraint, see hundreds of new options regenerate, and explore the trade-offs live. No overnight runs, no manual setup per site.
Second, the output would be explained. Every layout would come with an AI-generated rationale describing what it optimized for, what it traded away, and where it pushed against site constraints. The transparency problem becomes a transparency feature.
Third, the workflow would integrate Bonava's actual data sources. Their land bank, their typology library, their market data, their cost models. The 2020 version treated each of these as a separate input. The current version treats them as one connected feasibility surface.
The case is the same. Predefined products, variable sites, the need for fast and structured feasibility. The tools have caught up.
Looking back, the framing that has aged best is the audience framing. We argued that the most important consequence of generative design was not faster design. It was that it gave different disciplines a shared, fact-based vocabulary to evaluate options together. Developers, architects, business intelligence, and eventually municipal stakeholders could look at the same data and reach decisions earlier.
This was true in 2020, and it is more true now. The bottleneck in early-stage development is rarely the geometry. It is the alignment between people who need to agree on what to build before any capital moves. Tools that compress that alignment are the ones that actually change outcomes.
The Bonava collaboration was not a product. It was a proof of concept that helped us see what would eventually need to be built. Five years of building on that insight has clarified what was missing then and what now exists. The case has not changed. The means have.



